The Challenge of AI Visibility for Brands (Part 1)
Share
Summary
SOCi’s 2026 Local Visibility Index introduces a new framework for measuring AI visibility for multi-location brands across ChatGPT, Gemini, and Perplexity. Instead of rank tracking, the study uses a “% Recommended” metric to assess how often brands appear in the top AI-generated local recommendations, revealing stricter selection thresholds than traditional search.
SOCi’s 2026 Local Visibility Index (LVI) is the first study to assess AI visibility for multi-location brands. Broadly, our findings show that AI platforms including ChatGPT, Gemini, and Perplexity are much more selective than traditional search engines when choosing which local businesses to recommend.
We found, for instance, that Gemini recommended our target brands only 11% of the time, whereas the same brands appeared 36% of the time in the Google 3-Pack. The threshold for selection is stricter with AI, with the average cited business on ChatGPT having a rating of 4.3 stars, compared to 4.2 stars for the average business in Google’s traditional local results.
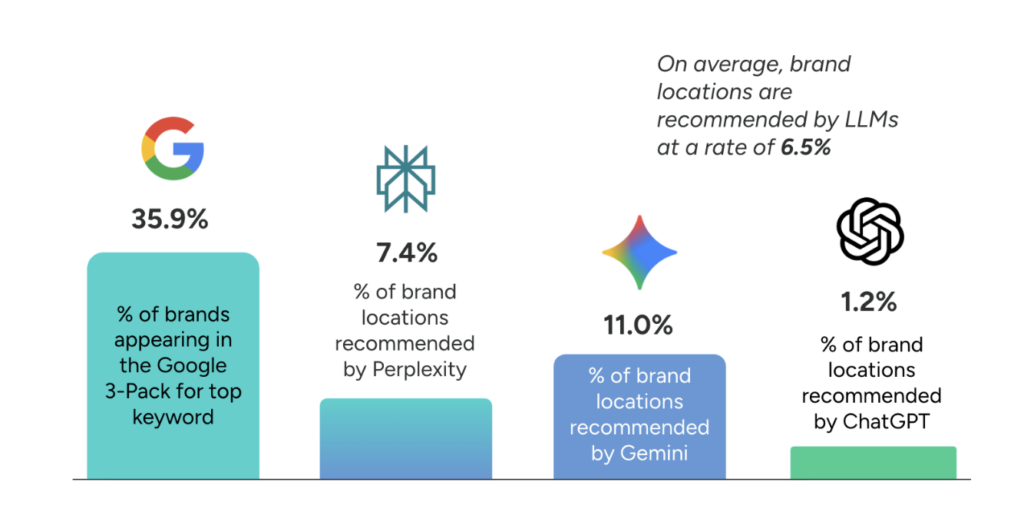
These results pose a challenge for multi-location brands, who do not appear as often in AI recommendations as do local SMBs. But how do we define AI visibility in the first place?
This is not as straightforward a question as it might appear. For many years, search marketers have relied on rank tracking to track online visibility for websites and local businesses. This was never a perfect solution, because personalization, including the physical location of the user, has a huge influence on rank position. However, if you repeat the same query under the same circumstances over time, rank position provides an indicator of relative growth or decline; and in recent years, grid-based ranking reports that check for rank position across a set geographical area have made rank tracking even more precise and useful.
But rank tracking is pointless in an AI context. As Rand Fishkin made clear in a recent study, asking an AI tool the same question 100 times is likely to present 100 different answers, and if those answers include a list of options (such as when recommending local businesses), different businesses may appear or disappear from lists of differing lengths with no apparent rhyme or reason.
This is because AI tools are probabilistic, rather than being controlled by algorithms whose outcomes are, given enough information, predictable. ChatGPT or Gemini, when asked to recommend a local business, may offer three options or five, or just one, depending on the query, and if you ask the question again, different options might appear in a different order.
We were conscious of this problem when building the 2026 LVI, and for that reason we focused on the concept of AI visibility as opposed to AI ranking.
A few basic facts about AI platforms informed our approach:
Users are likely to enter a broad range of queries that are longer, more conversational, and more nuanced than with traditional search.
AI results may differ significantly for different users or for the same query asked at different times.
Personalization of AI results may also play a significant role in differentiating results across users.
We wanted to address these complexities while establishing a method of measurement that could be repeated consistently across thousands of business locations. So we made the following decisions:
- Rather than trying to devise a comprehensive list of more specific questions people might ask about local businesses across multiple industries, we decided that the model question, “Can you recommend businesses of X type in Y market?” would be a good stand-in for a broad range of possible queries. After all, if a business doesn’t make the cut for this basic query, it’s unlikely to be visible in AI answers.
- We repeated this model question for every audited location of each brand, collecting a set of responses that represented a statistically valid sample of all of a brand’s locations. (The average brand in the LVI was represented by approximately 67 locations.)
- For each query, we asked the AI platform to recommend 10 businesses, but we only looked for our target brand in the first 5 results. We did not track rank position for these results, knowing that rank and even number of results would likely differ from query to query. Instead, we flagged a brand location as “likely to be recommended” if it appeared in the first 5 results. (Interestingly, brands were more likely to appear in the first 5 results than in positions 6-10.)
With this approach, we were able to produce our own version of Rand Fishkin’s experiment of repeating the same query multiple times and assessing how often a given result appeared across all instances. For us, the question was: how often does a given brand appear in AI recommendations across all of its locations, and how does this compare to the benchmark for brands in that industry?
The result is a metric we call % Recommended, one of the key metrics in the AI category of the LVI which we applied to ChatGPT, Gemini, and Perplexity.
Though % Recommended is not a perfect metric, it’s likely that there are no perfect metrics in the emerging field of AI optimization. That said, this is a metric that can be tracked over time, as with search ranking in the past, to give a picture of a brand’s visibility trend at the local level in AI platforms.
Related Articles




